



2. 湖南财政经济学院信息管理系, 湖南 长沙 410205
2. Department of Information Management, Hunan University of Finance and Economics, Changsha 410205, China
1 引言
高速铁路无砟轨道承载着高速列车的通行,其质量好坏直接关系着列车的运营安全,但高速铁路客运专线正式投运时间较短,相关病害检测工作开展相对滞后. 目前,无砟轨道的检测方法主要是探地雷达检测法[1, 2],为满足提速线路和高速线路轨道检测的需要,我国采用激光摄像测量技术研发了GJ-6型轨道检测系统[3]. 但是这些检测方法对于高速铁路轨道的表层病害检测的识别准确率不高,为此,本文提出基于视觉注意力模型的高速铁路轨道病害检测.
通过安装在高速动车组车头底部3台不同位置的CCD(charge coupled device)高清相机,拍摄列车行驶中的视频,然后对视频中病害区域进行检测. 鉴于病害区域与正常区域有着明显不同,本文将视觉注意机制[4]引入轨道病害检测. 由于视觉注意力模型忽略了不相关的信息和图像的冗余信息,并模拟人类视觉系统对场景的理解,不需要预先对场景信息进行训练,能够准确地提取病害区域,并提高了图像处理速度. 在众多视觉注意力模型中,Toet[5]引入了自下而上的多尺度显著度量(MCC)来构建视觉显著性模型,选取CIELab色彩空间的颜色作为图像的局部特征,以此计算图像显著性,并采用多尺度对比方法降低背景显著度以提高目标的显著值; David[6]选取RGB(red green blue)空间颜色、 亮度、 方向特征,将神经网络引入显著性计算,得到了包含多个显著区域的显著图,各显著区域通过竞争获得注意力焦点,以实现视觉注意力的转移; Guo[7]以颜色作为特征,将原图像进行多尺度分解,在每个尺度上构造一个滑动窗口,并计算该尺度下的显著性,然后将得到的多尺度显著图进行自适应阈值融合得到最终显著图; Naveed[8]选取图像的颜色、 亮度特征,利用周边特征差异性得到空间显著图,利用帧间特征差异性得到运动显著图,然后使用非线性加权融合机制将两个显著图进行融合,并采用自适应阈值方法加大图像中央区域的视觉显著度.
本文提出了基于视觉注意力模型的高速铁路轨道病害检测方法. 采用稀疏采样和核密度估计的视觉注意力模型,得到高速铁路轨道的显著图,从而检测出病害区域. 在此基础上,利用生成模型和EM(expectation maximization)算法,结合已标记样本和未标记样本提出了高速铁路轨道病害半监督分类方法[9],解决了病害分类中的小样本问题,即利用已有的少量已标记样本初始化分类器,然后利用大量未标记样本,通过递归计算方式对该分类器进行优化,直到包含所有样本的似然函数收敛到局部极大值. 对于待测样本,利用训练好的分类器,计算其在各类别分布函数下的最大后验概率,从而实现对轨道病害图像的准确分类. 对3种典型的轨道病害进行了实验,结果表明,该方法具有很高的检测率和识别率.
2 基于视觉注意力模型的轨道病害检测由于视频图像中病害区域与周围正常轨道区域的特征差异较大,因此病害区域具有较高的显著性,所以可将轨道病害检测转化为车载视频中显著区域的检测. 本文以待检测像素点为中心,采用圆柱体结构进行稀疏采样,得到周边临近像素点,以颜色作为特征,计算待测像素点与周边像素点的特征差异,再利用贝叶斯概率模型判断待测像素点的显著性,从而检测出病害区域.
2.1 圆柱体的稀疏采样把视频看作一个由图像空间平面(x,y)和时间轴t构成的三维时空(x-y-t)中的图像序列,在三维时空坐标系(x-y-t)中,一帧一帧的图像紧密排列,组成一个致密的包含很多像素点的空间结构.对于每个像素点定义其时空坐标为(x,y,t),在视频空间的显著性检测中,就是计算该像素点与其周围其它像素点的差异性.为了确定这些周围其它像素点,本文以待检测像素点为中心,以r为半径,以h为高(即取h帧图像),建立一个圆柱形结构,如图 1所示,图中黑点为待检测像素点,圆柱体内部的其它点就是该点的周围其它像素点.
 |
| 图 1 圆柱形结构的稀疏采样Fig. 1 Sparse sampling of the cylindrical structure |
计算显著性时,如果把上述周围点都考虑进去的话,计算量太大,检测速度太慢,为此,采用稀疏采样方法来选择周围像素点,本文不考虑圆柱体内部的像素点,只在圆柱面上均匀地进行像素点采样,即在每个圆周上进行等角度采样,图 1展示了稀疏采样的模型,黑点表示待测像素点,灰色点表示采样像素点. 其中,待测像素点所在的小圆上的像素点与待测像素点特征差异反映了待测像素点的空间显著性,而其它小圆上的像素点与待测像素点特征差异反映了待测像素点的时间显著性,故这些稀疏采样像素点可用于显著性计算,由于这种稀疏采样方法大大减少了显著性计算中周围点的数量,从而很大程度上提高了计算速度.
2.2 显著性测量设x=(x,y,t)代表视频图像中待测像素点的时空坐标,令V(x)=[L(x),a(x),b(x)]表示该时空点的特征向量,其中L(x)为CIELab色彩空间的亮度,a(x)和b(x)分别为CIELab色彩空间的颜色对立维度.
另外,设Hx为一个二进制随机变量,用于判断像素点是否为显著点. 如果Hx=1,那么该像素点是显著点; 如果Hx=0,那么该像素点是非显著点. 本质上,像素点的显著性计算依赖于概率p(Hx=1V(x),x)的值,将其简写为p(1V(x),x). 利用贝叶斯理论可得到:



采用文中的圆柱体稀疏采样,很容易得到:

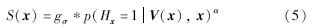
实验中发现采用某一个固定参数圆柱体稀疏采样时,对于不同大小病害的显著图检测效果不同. 如果采样圆柱体比较小,由于待测像素点与周边像素点距离较近,它们之间特征差异不够明显,使得显著点无法检测出来;而采样圆柱体比较大,由于周边像素点距离过远,像素点之间特征差异可能很大,将导致非显著点误判为显著点.因此,本文采用了多尺度计算显著图的方法,选择了M个不同大小的圆柱体,然后计算不同尺度下的显著图,将其平均值作为视频的显著图. 令r=[r1,2r1,…,Mr1],h=[h1,2h1,…,Mh1](文中取多尺度数M=3),则图像显著图为
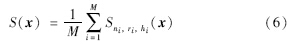
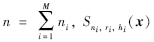 为第i个尺度下的显著图,根据式(5)计算得到.
3 基于生成模型的轨道病害分类
为第i个尺度下的显著图,根据式(5)计算得到.
3 基于生成模型的轨道病害分类典型的轨道表层病害包括轨道板裂纹、宽窄缝拉裂和剥落等,由于高速铁路专线投运时间较短,轨道表层病害的已知样本较少,因此病害图像分类存在小样本问题,为此,采用基于生成模型的最大似然估计的半监督分类方法,利用已有的少量已标记样本初始化分类器,然后用大量未标记样本,通过递归计算方式对分类器进行优化,直到包含所有样本的似然函数收敛到局部极大值.对于待测样本,利用得到的分类器,计算其在各类别分布函数下的后验概率,以此进行分类. 本文以病害区域的颜色直方图、 纹理特征、 SIFT(scale invariant feature transform)特征[10]作为分类器的输入.
3.1 概率生成模型假设轨道图像是由一个包含c类的混合模型生成的,且每个混合成分都满足一个特定的分布p(Xθi),那么,数据的概率生成模型可表示为

样本集包括未标记样本和已标记样本,即D=L+U={(X1,Y1),…,(Xl,Yl),Xl+1,…,Xl+u},Y∈C={1,2,…,c},l为已标记样本数,u为未标记样本数.由于它们是由同一个混合模型生成的,所以其对数似然函数可写成下列形式:

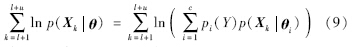
将(9)式代入(8)式得到:

与上述对数似然函数最大值对应的参数就是要估计的参数.
3.3 基于EM算法的分类参数估计利用EM算法来估计概率生成模型的参数,EM算法是一个递归算法,包括E步和M步,详细的推导过程参见文[11].
E步: 应用对数似然函数(式(10))求未标记样本的概率值,即预测未标记样本的类别:

M步: 在已知当前未标记样本的预测类别之后,求似然函数取极大值时各参数的取值,即p(Y)、 μ(均值向量)和Σ(协方差矩阵):

不断重复E步和M步,直到收敛. 其中收敛判别条件为: 对数似然函数在相邻两次递归之间变化很小.
3.4 基于生成模型的轨道病害分类利用训练好的分类器,可识别提取的病害,首先根据待分类病害的颜色直方图、 纹理特征、 SIFT特征分别计算其在每个类别中的概率p(YX); 然后,根据概率p(YX)进行分类: 若该样本在哪一个类别分布函数下的后验概率p(YX)最大,它便属于哪一类.
使用贝叶斯规则求最大后验概率:

由于采用的生成模型是假设高斯混合分布的,故式中p(X|Y)可由下式计算得到:

基于生成模型的轨道病害分类步骤如下:
(1) 训练分类器
1) 对于训练样本集D,估计每个类别的先验概率p(Y).
2) 计算每个类别的均值向量和协方差矩阵,即估计参数θi=μi,Σi
(2) 轨道病害分类
计算待分类病害样本对应各类别的后验概率,然后根据下式分类:
Y*→X=argYmaxp(YX)
4 实验为验证文中算法的有效性,实验取一段高速铁路车载视频对轨道病害进行检测与分类. 实验视频共计30 min,视频图像分辨率为1 280×800的彩色图像,帧率为30帧/s. 实验时,采用VC++来编程,实验的硬件配置如下: Intel酷睿2代四核CPU处理器(2.7 GHz)、 4 G内存、 独立显卡,操作系统是Windows 7.
4.1 实验及结果实验1 参数选取
圆柱体的尺度对病害的检测有很大影响,圆柱体比较小,病害可能无法检测出来; 而圆柱体比较大,可能将正常区域误判为病害区域. 另外采样点的个数影响检测准确率和检测速度. 为此,本文通过实验确定参数组r1、 h1、 n的选取. 实验共有54 000帧图像,其中包含病害的图像共436帧,病害的检测率δ=检测出的病害数/总病害数×100%.
实验中,在各圆周上等角度α采样,故整个圆柱体上的采样像素点数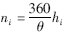 ,其中α取{1°,2°,…,90°}(除去
,其中α取{1°,2°,…,90°}(除去 不为整数的α值),因此n的选择就是要确定α. 实验中r1、 h1分别取正整数,当r1、 h1变化时,病害检测率随α变化的曲线如图 2所示.
不为整数的α值),因此n的选择就是要确定α. 实验中r1、 h1分别取正整数,当r1、 h1变化时,病害检测率随α变化的曲线如图 2所示.
 |
| 图 2 不同r1、 h1、 α的病害检测率曲线Fig. 2 Detection rate curves of damage at different r1,h1 and α |
由图 2可看出: 1) 对于不同的r1、 h1,当1°≤α≤12°时,病害检测率较高且变化不大,当α>12°时,病害检测率明显下降. 在保证检测率高的前提下,考虑到采样点越少,计算速度越快,故文中取α=12°,此时每个圆周上的采样点为30个; 2) r1=15、 h1=3对应的病害检测率曲线位于图的最上方,也就是说在α(或n)相同的情况下,r1=15、 h1=3时病害检测率最大.
图 3为当α=12°时,病害检测率随r1、 h1变化的关系. 图 3同样表明当α=12°、 r1=15、 h1=3时,病害检测率最大. 故参数取α=12°、 r1=15、 h1=3,相应的多尺度下的各参数为r=[15, 30, 45],h=[3, 6, 9],n=[90, 180, 270].
 |
| 图 3 不同r1、 h1的病害检测率曲线(α=12°)Fig. 3 Detection rate curve of damage at different r1 and h1 |
实验2 轨道病害检测
利用文中方法、 Toet方法[5]、 David方法[6]、 Guo方法[7]、 Naveed方法[8]进行轨道病害检测对比实验,实验结果如表 1所示. 本文方法检测出430帧病害图,检测率为δ=98.6%,与其它方法相比,检测率高、检测速度快.
图 4为轨道病害实例图,其中左边为宽窄缝拉裂,中间两幅为轨道板裂缝,右边为轨道剥落. 图 5的(a)、 (b)、 (c)、 (d)分别为文中方法、 Toet方法[5]、 David方法[6]、 Naveed方法[8]的检测结果. 从图 5可知,其它几种方法检测的病害区域不完整或者位置有所偏差,而本文方法检测到的病害区域和位置与实际情况非常吻合.
 |
| 图 4 轨道病害实例Fig. 4 Examples of track damage |
 |
| 图 5 各种方法的检测结果比较Fig. 5 Detection results of different method |
本文以受试者工作特征(ROC)曲线[12]来评价检测到的病害区域与实际病害区域吻合程度. ROC曲线越靠近左上角,ROC曲线下面积(AUC)越大,吻合程度越高. 本文使用了类似文[12]的方法,首先调整阈值从零到最大像素值,并计算真阳性(TPR)和假阳性值(FPR),然后计算ROC曲线下的面积得到AUC值. 图 6为上述几种方法的ROC曲线,表 2给出了ROC曲线下对应的面积(AUC),从表中可以看出,文中方法的AUC最大,说明其病害检测效果最好.
 |
| 图 6 受试者工作特征(ROC)曲线Fig. 6 The receiver operating characteristic (ROC)curve |
实验3 轨道病害分类
利用文中轨道病害分类法对检测出的430幅含有轨道病害的图像进行分类,其中无病害图像15幅,宽窄缝拉裂图像151幅,轨道板裂纹图像143幅,剥落图像121幅. 实验结果如表 3所示. 实验结果表明文中方法平均分类准确率为99.3%,其中2个宽窄缝拉裂图像被误判为轨道板裂缝图像,2个轨道板裂缝图像分别被误判为宽窄缝拉裂图像和剥落图像.
| 类别 | 个数 | 正确识别数 | 误判数 | 正确率 |
| 宽窄缝拉裂 | 151 | 149 | 1 | 98.7% |
| 轨道板裂纹 | 143 | 142 | 2 | 99.3% |
| 剥落 | 121 | 120 | 1 | 99.2% |
| 无缺陷 | 15 | 15 | 0 | 100.0% |
另外,利用文中方法与SVM(support vector machine)[13]、 Adaboost[14]、 PLSA(probabilistic latent semantic analysis)[15]、 神经网络[16]方法进行了对比实验,表 4给出了各种方法的识别率. 由表可知,文中基于生成模型的分类方法比其它分类方法具有更高的分类正确率.
(1) 轨道病害检测结果表明本文提出的方法检测率高,计算速度快. 这是因为,Toet方法、 David方法、 Guo方法只在当前帧内计算待测像素点与周边像素点的特征差异,忽略了运动显著性,而Naveed方法虽然将模型扩展到三维空间,但是在计算运动显著性时,仅仅利用前一帧图像,且采用简单的帧间差分法获得运动显著图,因此病害检测率相对低一些. 文中算法采用圆柱体采样,包含了当前帧和前几帧的周边像素点,因此,在计算视觉显著性时利用了更多的周边像素点特征信息,从而获得更高的显著性检测率. 另外,在计算过程中,前面几种方法需要对采样窗口内所有邻近像素点进行计算,计算量大,而本文采用圆柱形稀疏采样的方法,只在圆柱体表面进行等角度稀疏采样,忽略圆柱体内部像素点,大大减少了计算量,从而加快了计算速度.
(2)轨道病害分类结果表明本文提出的方法具有很高的正确分类率.这是由于SVM、Adaboost、PLSA、神经网络等方法都是有监督分类方法,仅仅借助已标记样本对分类器进行训练,在已标记样本数目较少的时候,得到的分类器不够准确,用于轨道病害分类时,会产生分类错误.而本文采用半监督分类器,结合少量已标注样本与大量未标注样本对分类器进行训练,提高了分类器的正确率.
5 总结高速铁路轨道病害检测是高速列车安全行驶的保障,本文提出了基于视觉注意力模型的高速铁路轨道病害检测方法,采用稀疏采样和核密度估计的视觉注意力模型分析高速铁路轨道视频的显著性,准确地检测出轨道病害区域;提出了基于生成模型的高速铁路轨道病害分类与识别方法,利用半监督分类方法,结合已标记样本和未标记样本训练分类器,解决了病害图像分类中的小样本问题. 实验证明,文中方法能很好地检测和区分轨道板裂纹、 宽窄缝拉裂和剥落几种常见的轨道表面病害.
尽管本文方法能够准确地检测与识别高速铁路轨道病害,但是并不能确定轨道的破损程度.如何在检测与识别轨道病害的同时,对高速铁路轨道破损程度进行评定是今后的一个重点研究方向.
| [1] | Jack R, Jackson P. Imaging attributes of railway track formation and ballast using ground probing radar[J]. NDT & E International, 1999, 32(8): 457-462. |
| [2] | Hugenschmidt J. Railway track inspection using GPR[J]. Journal of Applied Geophysics, 2000, 43(2): 147-155. |
| [3] | Wei S B, Li Y, Zhao Y F, et al. Design and development of GJ-6 track detection system[J]. Railway Engineering, 2012(2): 97-100. |
| [4] | Robert I F, Yushchenko L. Visual attention model for computer vision[J]. Biologically Inspired Cognitive Architectures, 2014, 7(1): 26-38. |
| [5] | Toet A. Computational versus psychophysical bottom-up image saliency: A comparative evaluation study[J]. Pattern Analysis and Machine Intelligence, 2011, 33(11): 2131-2146. |
| [6] | David F, Odelia S, Juan F. A saliency-based bottom-up visual attention model for dynamic scenes analysis[J]. Biological Cybernetics, 2013, 107(2): 141-160. |
| [7] | Guo M W, Zhao Y Z, Zhang C B, et al. Fast object detection based on selective visual attention[J]. Neurocomputing, 2014, 9(1): 1-14. |
| [8] | Naveed E, Irfan M, Sung W B. Feature aggregation based visual attention model for video summarization[J]. Computers and Electrical Engineering, 2014, 40(3): 993-1005. |
| [9] | Araken S, Anne C. Applying semi-supervised learning in hierarchical multi-label classification[J]. Expert Systems with Applications, 2014, 41(14): 6075-6085. |
| [10] | 朱韶平, 夏利民, 彭东亮. 基于图像和GM-PLSA模型的物品推荐方法[J]. 系统工程, 2013, 31(12): 109-115. Zhu S P, Xia L M, Peng D L. Product recommendation based on image content and GM-PLSA model[J]. Systems Engineering, 2013, 31(12): 109-115. |
| [11] | Redner R A, Walker H F. Mixture density, maximum likelihood and the EM algorithm[J]. SIAM Review, 1984, 26(2): 195-239. |
| [12] | Wang W N, Cai D, Xu X M, et al. Visual saliency detection based on region descriptors and prior knowledge[J]. Signal Processing: Image Communication, 2014, 29(3): 424-433. |
| [13] | Maksim L, Matthias H, Bernt S. Learning using privileged information: SVM+ and weighted SVM[J]. Neural Networks, 2014, 53(1): 95-108. |
| [14] | Mathanker S K, Weckler P R, Bowser T J. AdaBoost classifiers for pecan defect classification[J]. Computers and Electronics in Agriculture, 2011, 77(1): 60-68. |
| [15] | Nikolopoulos S, Zafeiriou S, Patras I. High order PLSA for indexing tagged images[J]. Signal Processing, 2013, 93(8): 2212-2228. |
| [16] | Mark E, Chrisina J. Evaluation of hyper box neural network learning for classification[J]. Neurocomputing, 2014, 113(10): 249-257. |