



2. 中国科学院大学, 北京 100049;
3. 沈阳理工大学, 辽宁 沈阳 110159
2. University of Chinese Academy of Sciences, Beijing 100049, China;
3. Shenyang Ligong University, Shenyang 110159, China
1 引言
视觉目标跟踪是计算机视觉领域的研究热点之一,广泛地应用于智能视频监控、 智能交通监管、 汽车自动或辅助驾驶、 机器人导航和人机交互等领域[1]. 在过去的几十年间,出现了大量的跟踪方法及相关技术. 但在实际中目标跟踪面临的主要困难是运动目标的外观在运动过程中会受外界环境的影响而产生变化,这些影响因素包括: 光照变化、 部分或完全遮挡、 目标外观变化、 复杂背景环境干扰、 目标非规则或快速运动等因素. 因此,设计一个鲁棒的目标表观模型成为目标跟踪的极富挑战性的任务[2].
根据不同的外观表示方法,近期提出的跟踪模型可被分为两类: 生成模型和判别模型. 生成模型首先学习一个表观模型来表示目标,然后在每一帧搜索与已学习的表观模型最相似的目标表观. Black等[3]提出了一个离线子空间表观模型,但是该离线学习的表观模型难以适应目标外观的变化. 为了处理外观的变化,人们提出了一些在线模型,例如WLS(wander-lost-stable)跟踪器[4]和IVT(incremental visual tracking)方法[5]. Adam等[6]利用多分段设计了一个对部分遮挡比较鲁棒的表观模型. 最近,稀疏表达[7]被应用于目标跟踪,对部分遮挡、 光照变化和姿态的改变表现出了良好的性能. 这些生成模型都没有考虑背景信息,丢弃了一些把目标从背景中判别出来的非常有用的信息.
判别模型把跟踪问题看作是将目标从背景中分离出来的二分类问题. 这些方法也称为检测跟踪法,将跟踪问题看作是一个检测任务[8]. 首先利用从当前帧图像中抽取的样本,以在线的方式训练一个分类器,对下一帧图像,在前一帧目标位置附近利用滑动窗方法,抽取新的样本. 将事先训练好的分类器应用于这些样本,得分最高的样本的位置就是目标在当前帧的新位置. Avidan等[9]利用包围目标的矩形框和环绕该框的矩形框中的带标记的像素,使用boosting方法训练强分类器,然后使用mean-shift方法[10],在新的图像帧中,寻找分类器得分最高的位置作为新的目标位置. 该方法中使用的特征包含影响分类器性能的大量的无关信息. Collins等[11]证明了以在线的方式选择判别性的特征可以极大地提高跟踪性能. Grabner等[12]提出了在线boosting特征选择方法. 这些判别方法只使用一个正样本和多个负样本来更新分类器,可能会降低分类器的性能,导致跟踪失败(漂移). 为了减弱漂移问题,Grabner等[13]提出了半监督的方法,仅标识第一帧的样本而不标识后续帧的样本,来训练分类器. 但这种方法舍弃了一些非常有用的信息. MIL(multiple instance learning)跟踪器[14]将正负样本分别放入正负包,利用包相似函数在线训练分类器. 该方法中使用的模型没有考虑正样本的重要性,因此,该跟踪器可能会选择一些效果较小的正样本. 压缩跟踪(CT)[15]对跟踪目标的模板进行压缩,提取随机的多尺度特征,利用朴素的贝叶斯分类器进行目标的跟踪和分类器的更新,取得了较好的效果. 但该方法没有解决目标尺度变化的问题.
针对目标跟踪中的光照变化和部分遮挡问题,本文提出了一种结构化的带权的联合特征表观模型. 该模型将目标图像划分成若干图像块,这些图像块保持了固定的空间结构信息; 在每个图像块内分别计算局部颜色特征和纹理特征,加权后形成特征向量作为目标的表观特征. 在贝叶斯框架内,提出了一种跟踪方法. 算法的总体过程如图 1所示. 该方法在仿射变换空间内,利用随机函数提取不同尺度的候选目标图像,较好地解决了被跟踪目标的尺度变化问题.
 |
| 图 1 本文算法的流程图Fig. 1 The flow chat of the proposed method |
颜色特征是计算机视觉领域中应用最为广泛的特征,与其它的视觉特征相比,颜色特征对图像本身的尺寸、 方向、 视角的依赖性较小,从而具有较高的鲁棒性. 因为HIS(hue intensity saturation)颜色空间与人类的视觉系统比较一致,利用式(1)将图像从RGB(red green blue)颜色空间转换到HIS空间:
本文选择颜色特征中的一阶矩(均值)和二阶矩(方差)[16]来表示图像中颜色的分布,其数学定义如下:
计算HIS颜色模型中H、 S和I通道的一阶矩和二阶矩,得到图像的颜色特征FC=[Fμ,Fσ],其中Fμ=α1μH+α2μS+α3μI,Fσ=α1σH+α2σS+α3σI,α1、 α2、 α3分别是H、 S和I通道的权重.
2.2 纹理特征图像二维熵是一种纹理特征的统计形式,既反映了图像灰度的聚集特征,也反映了灰度分布的空间特征. 选择图像的邻域灰度均值作为灰度分布的空间特征量,与图像的像素灰度值组成二元组,记为(i,j),其中i表示像素的灰度值,j表示邻域灰度均值:

设当前帧图像为I(x,y),候选目标图像为T(x,y)∈I,用矩阵B将候选目标图像T划分为m×n个图像块:
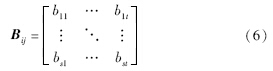
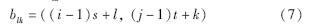
在每个图像块中分别计算颜色矩特征和二维熵特征,并将这些特征形成特征向量F=[FiC,FiT]mni=1,FiC表示第i个图像块的颜色特征分量,FiT表示第i个图像块的纹理特征分量:
在目标跟踪过程中,当发生部分遮挡时,不同的图像块所起的作用是不同的. 被遮挡的图像块所起的作用小,而没有被遮挡的图像块所起的作用大,因此对不同的图像块设置不同的权值. 在跟踪过程中,根据相邻两帧被跟踪目标各特征分量的相似程度自适应地调整各图像块的权值. 设F=[F1,F2,…,Fmn],Fi表示第i个图像块的特征分量,则有:
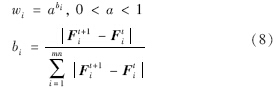
在不同的视频序列图像跟踪中,颜色特征和纹理特征的作用是不同的,因此对这两部分特征分量设置不同的权值wc和wt. 设Fti=[FtCi,FtTi],FtCi和FtTi分别表示第t帧第i个图像块的颜色特征分量和纹理特征分量:
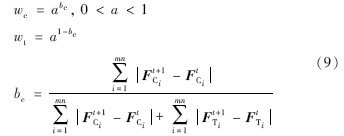
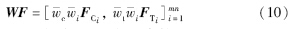
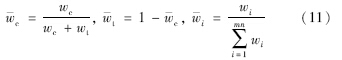
模型的示意图如图 2所示.
 |
| 图 2 本文表观模型示意图Fig. 2 Illustration of the proposed appearance model |
本文提出的跟踪算法在朴素贝叶斯框架内进行. 假设被跟踪的目标在第1帧中的位置是已知的,在该位置附近采样一些正样本,远离该位置采样一些负样本来训练分类器. 在接下来的每一帧图像中,采用类似的方法获取正样本和负样本来更新分类器. 为了预测目标在下一帧中的位置,在当前的跟踪位置周围获得一些样本,由分类器得分最高的作为跟踪的结果. 3.1 训练样本
设gt(x)=[xc,yc,w,h]∈R4表示样本x在第t帧的几何参数,pt(x)=[p1,…,p6]∈R6表示其仿射变换参数. 其中,(xc,yc)表示样本的中心坐标,(w,h)表示被跟踪目标图像的宽度和高度. 当获得了被跟踪目标在当前帧的仿射变换参数,就可以利用随机函数生成n组随机数,与当前帧跟踪目标的仿射变换参数相加,获得n组正样本xp的仿射变换参数. 该过程可以表示为
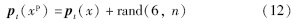
由这些仿射变换参数计算相应的几何参数,就能得到不同位置、 不同尺度的正样本图像.
在正样本的周围选择负样本,若正负样本间发生大面积的重合,正负样本的间隔就会相应减小,利用这些正负样本训练出来的分类器错分的可能性会增大. 因此本文选择的负样本尽量不与正样本重合. 设l(x)=(xc,yc)表示样本x的中心位置坐标,利用下面的公式获得负样本的xn的中心位置坐标:
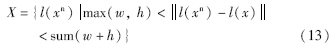
其中,X表示负样本图像的中心坐标的集合. 进一步就可以获得与样本x同尺度的负样本图像,这些负样本图像与正样本图像之间的重叠非常小.
图 3显示了一些选择的正、 负样本图像. 红色矩形框表示的是正样本,绿色矩形框表示的是负样本图像. 其中的正样本图像尺度不同,而负样本的尺度是相同的,且正、 负样本图像间基本没有重叠.
 |
| 图 3 样本选择图示Fig. 3 Illustration of sample selection |
贝叶斯分类器[18]是指基于贝叶斯理论的分类器,朴素是指特征之间相互独立. 贝叶斯分类器的原理是根据先验概率和似然函数计算后验概率,某类对应的后验概率大,对象就分为哪类. 根据贝叶斯理论,当特征为Fn,类别为C时,贝叶斯分类器的条件概率模型为
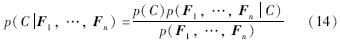
式(14)中的分母与类别C无关,在分类时不提供判别信息,不作考虑. 因此,分类只与分子有关,当贝叶斯模型满足朴素这个假设时,分子等价于:
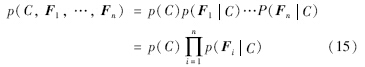
这就只需要估计每个特征的似然函数P(FnC),以及类别的先验概率p(C).
在本文的目标跟踪中,仅涉及到两类,即目标和背景,故针对样本x,可用下面的公式进行估计:
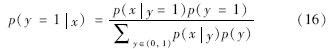
朴素贝叶斯假设特征的每个分量之间是相互独立的,即各个特征分量对分类的贡献是彼此无关的. 设v=[v1,…,vmn]表示本文表观模型的特征向量,每个特征分量vi对分类的贡献是独立的,朴素贝叶斯分类器可表示为
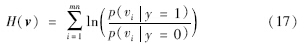
从高维空间投影得到的特征向量总是满足高斯分布[19],因此,分类器H(v)的条件分布p(viy=1)和p(viy=0)是带有4个参数(μ1i,σ1i,μ0i,σ0i)的高斯分布:
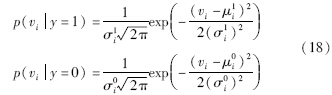
其中,μ1i、 σ1i、 μ0i、 σ0i分别是正、 负样本的第i个特征分量的均值与方差.
跟踪过程中,使用如下的更新策略[15]:
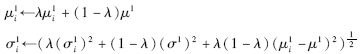
其中,0<λ<1是学习效率参数,
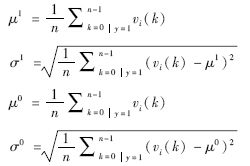 3.3 跟踪方法
3.3 跟踪方法本文所提出的跟踪方法的主要步骤如下:
步骤1: 对输入的图像,由前一帧的跟踪结果,按式(12)计算当前帧候选目标图像的仿射变换参数; 由仿射变换,获得N个候选目标的图像.
步骤2: 由式(5)对每个候选目标图像分块,计算每块的颜色特征(式(2))和纹理特征(式(4)).
步骤3: 由式(8)和式(9)计算权值,并由式(11)进行归一化; 结合步骤2的特征,生成加权的联合特征向量v.
步骤4: 用式(17)对每个特征向量v进行计算,取N个值中的最大值所对应的候选目标图像作为当前帧的跟踪结果.
步骤5: 用式(12)采集当前帧图像的负样本,并计算其特征向量.
步骤6: 使用文中的更新策略更新分类器的参数.
4 实验结果与分析本文的跟踪方法及对比算法均是在PC机(IntelCoreTM 2 Duo CPU,2.29 GHz,2.00 GB)上实现,其软件环境为Matlab R2010b. 对于每一个视频序列,跟踪目标的初始位置在第1帧中手工确定. 被跟踪的目标图像被转化为32×32像素,划分为4×4块. 在每个图像块内分别计算颜色特征和纹理特征,形成一个48×1的特征向量. 考虑到人眼对色调最为敏感,本文选取H、 S和I通道的权重α1=0.6,α2=0.2,α3=0.2. 每个图像块的初始权值wi都设置为1/16,a的值取0.5,颜色分量和纹理分量的初始权值设置为0.5. 正样本的数量为400,负样本的数量不超过200. 分类器的初始均值与初始方差分别为1和0.
在几个具有代表性的视频序列上对本文的方法进行了测试,并与CT(compressive tracking)跟踪算法[15]、 MIL跟踪算法[14]、 L1(L1 minimization tracking)跟踪算法[7]和ASLSAM(adaptive structural local sparse appearance model)跟踪算法[20]进行了比较. 这些视频包括光照变化、 部分遮挡及尺度变化. 这些对比算法的代码使用的是作者发布的源代码.
4.1 定量比较使用中心位置差和每一帧的平均跟踪时间作为上述算法的评价指标,中心位置差用当前帧跟踪结果目标图像与标准目标位置图像的中心坐标的欧氏距离表示,平均跟踪时间为每一帧的处理时间,结果如表 1和表 2所示. 表中的红色字体和蓝色字体分别表示最好和次好的结果.
| ASLSAM | L1 | CT | MIL | Ours | |
| Singer1 | 11.39 | 30.88 | 56.19 | 24.87 | 12.27 |
| Trellis70 | 13.97 | 21.18 | 32.64 | 14.49 | 6.14 |
| Woman_sequence | 15.54 | 48.93 | 47.49 | 48.85 | 15.41 |
| Threepastshop2cor | 57.88 | 54.89 | 59.87 | 55.41 | 39.25 |
| Board | 20.29 | 96.49 | 84.27 | 65.77 | 16.81 |
| ASLSAM | L1 | CT | MIL | Ours | |
| Singer1 | 0.19 | 1.49 | 0.16 | 0.30 | 0.05 |
| Trellis | 0.12 | 1.20 | 0.09 | 0.29 | 0.05 |
| Woman_sequence | 0.11 | 1.27 | 0.10 | 0.27 | 0.05 |
| Threepastshop2cor | 0.16 | 1.35 | 0.12 | 0.29 | 0.05 |
| Board | 0.19 | 1.41 | 0.19 | 0.31 | 0.08 |
图 4显示的是两个典型序列图像的光照变化率,用每一帧目标图像和参考目标图像(第1帧)的平均亮度差,与参考目标图像的平均亮度的熵作为光照变化率. 图 5是代表性的遮挡序列图像的遮挡率,用目标被遮挡部分的面积与目标图像的面积的比值来表示. 图 6展示的是部分视频序列的中心位置差曲线图.
 |
| 图 4 光照变化率曲线图Fig. 4 Curve graph of illumination changing rate |
 |
| 图 5 遮挡率曲线图Fig. 5 Curve graph of occlusion rate |
 |
| 图 6 中心位置差曲线图Fig. 6 Curve graph of center location error |
从曲线图中可以看出,当光照变化比较平缓时,除L1算法外,本文方法及其它跟踪方法对光照变化有一定的适应性;但当存在剧烈光照变化时,本文方法和ASLSAM算法跟踪较好,其它算法则出现了明显的漂移现象.本文方法和ASLSAM算法对遮挡情况具有较好的鲁棒性.
4.2 定性比较光照变化严重地影响着跟踪的结果,特别是对于使用图像的灰度值作为特征的跟踪方法. 针对具有光照变化的视频序列的跟踪结果如图 7所示. 在Singer1视频序列(图 7(a))中,舞台的灯光变化剧烈,目标存在明显尺度变化. 在Trellis70视频序列(图 7(b))中,场景存在显著的光照变化. ASLSAM跟踪算法,因为其结构化的表观模型及基于稀疏表达的跟踪算法,能够较好地跟踪目标;而本文的表观模型由于具有不同权值的颜色特征和纹理特征,能减弱光照变化对跟踪的影响,因此能准确而又鲁棒地跟踪这些具有光照变化的目标. 其它跟踪方法,如CT跟踪方法、MIL跟踪方法和L1跟踪方法则受光照变化的影响较大,发生了漂移现象.
 |
| 图 7 光照变化视频序列的跟踪结果Fig. 7 Tracking results on videosequences with illumination variation |
部分遮挡是目标跟踪过程中一个普遍而又关键的问题. 事实上,许多跟踪算法,如MIL跟踪算法、 L1跟踪算法、 ASLSAM跟踪算法及本文方法都是用来解决部分遮挡问题的. 在Woman_sequence视频序列(图 8(a))中,目标存在姿态变化和长时间的部分遮挡. 当目标的下半部分被遮挡住的时候,CT跟踪算法、 MIL跟踪算法和L1跟踪算法都发生了跟丢的现象,而ASLSAM跟踪算法和本文的跟踪算法能准确地进行跟踪. 在Threepastshop2cor视频序列(图 8(b))中,目标不时地被另外两个人遮挡,而且其中的一个人还与目标在颜色和形状上很相似. 当目标被其中的一个人遮挡的时候,CT跟踪算法、 MIL跟踪算法和L1跟踪算法转而去跟踪与目标相似的另一个人. ASLSAM跟踪算法和本文方法能很好地处理这种遮挡情况,准确地跟踪目标.
 |
| 图 8 部分遮挡视频序列的跟踪结果Fig. 8 Tracking results on video sequences with partial occlusion |
在Board视频序列(图 9)中,目标存在一定程度的旋转,而背景则比较复杂. 当目标发生旋转或快速移动的时候,大多数跟踪算法发生漂移,而ASLSAM跟踪算法和本文算法因为结构化的表观模型,能准确地跟踪目标.
 |
| 图 9 复杂背景的视频序列的跟踪结果Fig. 9 Tracking results on video sequence with complex background |
针对单目标跟踪中光照变化和部分遮挡问题,本文提出了一种结构化的加权联合特征表观模型. 该模型既保留了被跟踪目标的空间结构信息,又考虑了目标的颜色和纹理特征,针对不同的视频序列,各特征分量采用自适应的权值. 将该模型与朴素贝叶斯理论相结合进行目标跟踪. 实验结果证明了本文方法的有效性.
| [1] | 刘世荣, 朱伟涛, 杨帆, 等. 基于多特征融合的粒子滤波目标跟踪算法[J]. 信息与控制, 2012, 41(6): 752-759. Liu S R, Zhu W T, Yang F, et al. Mulit-feature fusion based particle filter algorithm for object tracking[J]. Information and Control, 2012, 41(6): 752-759. |
| [2] | Tsagkatakis G, Savakis A. Online distance metric learning for object tracking[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2011, 21(12): 1810-1821. |
| [3] | Black M, Jepson A. Eigentracking: Robust matching and tracking of articulated objects using a view-based representation[C]//European Conference on Computer Vision. Berlin, Germany: Springer, 1996: 329-342. |
| [4] | Jepson A, Fleet D, El-Maraghi T. Robust online appearance models for visual tracking[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(3): 1296-1311. |
| [5] | Ross D, Lim J, Lin R, et al. Incremental learning for robust visual tracking[J]. International Journal of Computer Vision, 2008, 77(1): 125-141. |
| [6] | Adam A, Rivlin E, Shimshoni I. Robust fragments-based tracking using the integral histogram[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2006: 798-805. |
| [7] | Mei X, Ling H. Robust visual tracking using L1 minimization[C]//International Conference on Computer Vision. Berlin, Germany: Springer, 2009: 1436-1443. |
| [8] | Avidan S. Support vector tracking[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(5): 1064-1072. |
| [9] | Avidan S. Ensemble tracking[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(1): 261-271. |
| [10] | Comaniciu D, Ramesh V, Meer P. Kernel-based object tracking[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(2): 564-575. |
| [11] | Collins R, Liu Y, Leordeanu M. Online selection of discriminative tracking features[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(8): 1631-1643. |
| [12] | Grabner H, Grabner M, Bischof H. Real-time tracking via online boosting[C]//British Machine Vision Conference. Edinburgh, UK: British Machine Vision Association, 2006: 47-56. |
| [13] | Grabner H, Leistner C, Bischof H. Semi-supervised on-line boosting for robust tracking[C]//European Conference on Computer Vision. Berlin, Germnay: Springer, 2008: 234-247. |
| [14] | Babenko B, Yang M, Belongie S. Robust object tracking with online multiple instance learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(8): 1619-1632. |
| [15] | Zhang K, Zhang L, Yang M H. Real-time compressive tracking[C]//European Conference on Computer Vision. Berlin. Germany: Springer, 2012: 866-879. |
| [16] | 王东, 蒋炯辉, 周世生. 基于局部矢量匹配的颜色特征快速传递算法[J]. 信息与控制, 2010, 39(2): 252-256. Wang D, Jiang J H, Zhou S S. Fast color transfer between images based on local vector matching[J]. Information and Control, 2010, 39(2): 252-256. |
| [17] | 卢惠民, 张辉, 杨绍武, 等. 一种鲁棒的基于全向视觉的足球机器人自定位方法[J]. 机器人, 2010, 32(4): 553-559, 567.Lu H M, Zhang H, Yang S W, et al. A robust self-localization method based on omnidirectional vision for soccer robots[J]. Robot, 2010, 32(4): 553-559, 567. |
| [18] | 李旭升, 郭耀煌. 灵活的增强朴素贝叶斯分类器[J]. 信息与控制, 2007, 36(6): 690-695, 701. Li X S, Guo Y H. Flexible augmented naive Bayesian classifier[J]. Information and Control, 2007, 36(6): 690-695, 701. |
| [19] | Zhang K H, Song H H. Real-time visual tracking via online weighted multiple instance learning[J]. Pattern Recognition, 2013, 46(1): 397-411. |
| [20] | Jia X, Lu H C, Yang M H. Visual tracking via adaptive structural local sparse appearance model[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ, USA: IEEE, 2012: 793-805. |