



1 引言
导航是移动机器人的基础能力之一[1],是机器人完成其它任务的先决条件.国内外学者对此进行了大量的研究,传统的导航方法有:人工势场法[2-3]、遗传算法[4-5]、A*算法[6]等.而目前更具代表性的是对不同的导航方法进行结合[7-8].文[7]提出了一种结合Voronoi图法和势场法的导航方法,综合这两种方法分别在全局路径规划和局部避障的优势,实现了在密集障碍物环境下的导航;文[8]提出了一种结合路径跟随和特征提取的导航方法,通过获取视觉信息,在室内室外的混合场景中进行了有效导航.此外,随着传感器的不同,导航方法与策略也不尽相同,例如通过视觉传感器[9]、Kinect深度传感器[10]、激光测距仪(laser range finder,LRF)[11-15]等来实现导航,其中文[13]提出了一种基于激光测距仪求可行方向的移动机器人避障方法,较好地解决了激光测距仪在避障过程中因激光距离数据处理不全面而导致的盲区问题.文[14]提出的激光测距仪数据分析方法,强化了机器人对局部环境的认知能力.
然而,上述导航方法的建立都是基于环境场景的数学模型[16],因此移动机器人的导航性能很大程度上取决于建立的模型性能.而现实中环境模型通常是难以建立的,环境信息处理之艰难是普遍存在的问题[17].此外在这种机制下,导航过程中非必要的重复计算和决策浪费了大量计算资源和时间[18].受认知科学、神经生物学和心理学等学科的启发,近年来研究人员开始着眼于基于认知学习的方法来解决上述问题[19-22].所谓认知学习,即使机器人像人类一样经历从婴儿到成人的发育过程,逐渐学会日益复杂的非特定任务,并具有更强的自适应能力.这种心智发育的思想由美国密歇根州立大学的Weng教授提出,该文发表于2001年的《Science》上[23].基于这一思想,Weng提出了一种增量分层判别回归(incremental hierarchical discriminant regression,IHDR)算法[24],该算法通过建立一种知识库使机器人像人类一样对导航路径进行认知学习,并在线存入知识库中,之后再通过检索知识库实现预定路径的自主导航.但这种方法仅适合于静态场景下的导航,容易受到干扰,且对动态场景的适应能力不足并存在偏航风险.
考虑到基于学习机制的方法避免了复杂的场景建模,实时性好、效率高,而传统的控制方法包含反馈通道,鲁棒性好,本文结合这两种方法的优势提出一种基于学习机制的移动机器人自适应导航方法.该导航方法的主要特征在于:
(1) 对两种导航方法进行结合;
(2) 全局导航采用文[24]提出的IHDR算法,使移动机器人直接对全局导航路径进行认知学习和训练,摆脱了对建立环境模型的依赖,并结合局部避障算法进行背景避障;
(3) 基于文[13]中的求可行方向的方法,提出了一种基于最远距离优先机制的局部避障算法用于局部避障,使机器人在局部环境避障操作中,始终朝着逃离障碍区的方向行进.
本文实验部分选用激光测距仪感知周围环境,同时用于全局导航路径的学习和局部避障.激光测距仪具有高精度、数据量精简、视域宽阔、受环境光照影响小等特性.移动机器人在导航过程中对实时性要求高,故采用激光测距仪进行导航.本文提出的自适应导航方法解决了基于单一学习机制的导航方法对动态场景适应能力不足的问题,在基于IHDR算法导航的研究方法中,增加了避障判断环节.在MT-R移动机器人上的实验证实了本文导航方法的可行性.
2 单一学习机制存在的问题基于单一学习机制导航方法的特征在于,首先人为规划出供机器人行驶的最优导航路径,然后控制机器人沿着得到的最优导航路径进行运动并在线学习和训练,建立当前环境信息与机器人运动控制信息的映射关系,并将该映射关系存放入知识库中.环境信息的获取一般由传感器采集得到,如激光测距仪、Kinect深度传感器等;机器人的运动信息主要包括速度、位移等.此外,学习或训练的次数越多,数据量越大,知识库就越丰富.这种基于学习机制建立知识库的方法与传统的导航或路径规划方法相比,更加类似于人的心智发育或者学习过程.当机器人在线运行时,只需通过实时获取当前的环境信息,从中检索知识库便可得到相应的运动控制量,直接作为机器人的行为输出.
然而,该方法单纯依赖之前导航场景中预先建立的知识库,仅适用于静态场景下的学习.当新的导航场景存在动态变化、遮挡、相似物干扰等影响时,这种基于单一学习机制的导航,会因当前场景和知识库中场景之间的差异,产生错误判断,造成偏航.并且由于学习和检索过程中的误差客观存在,即使是在严格的静态场景中,也会有存在一定的偏航几率.一旦偏航发生,机器人碰撞等事故风险会大大增加.因此,这种导航方法存在动态场景适应力不足、无障碍信息反馈通道等问题.
本文在基于单一学习机制的导航系统基础之上,增加了修正偏差环节以应对动态场景.当获取环境信息时,首先进行数据判据,判断环境信息是否满足知识库检索条件.若满足,则基于学习机制进行导航;若不满足,则进行修正偏差(如进行避障),再进行导航.这样使得基于单一学习机制的导航具备了动态场景自适应能力. 图 1给出了单一学习机制导航系统框图及与改进后的自适应导航系统框图的对比.

|
| 图 1 两种导航方法对比框图 Figure 1 The contrast flow chart of two navigation methods |
自适应导航方法建立在学习机制基础之上,通过激光测距仪获取机器人与周围物体的距离信息,在检索知识库之前增加了背景避障判断环节,采用基于IHDR算法的学习机制建立知识库,提出一种基于最远距离优先机制的局部避障算法进行避障操作,分别在3.1节和3.2节给出.
3.1 IHDR算法IHDR(incremental hierarchical discriminant regression,增量分层判别回归)算法是一种建立知识库并对其进行快速检索的算法.其中的知识库是一种树状结构,也称作IHDR树.
3.1.1 IHDR树的创建设机器人在线学习中获取了m组训练样本S={(xi,yi)|xi∈X,yi∈Y,i=1,2,…,m},其中样本中包含着映射关系f:X→Y,δy为Y空间的灵敏度值,q为每层中允许的最大聚类数[24],以下每一个聚类都表示IHDR树中的一个节点.
Step 1 先对Y空间的向量y1,y2,y3,…,ym按以下方式进行聚类:
(1) 先设y1为聚类中心.
(2) y2与y1求欧氏距离[24]D21,若D21 < δy,y2和y1归为一类,y1与y2的均值作为它们聚类的新聚类中心;若D21>δy,y2作为新的聚类,聚类中心为本身.
(3) yi(i=3,4,…,m)与现有聚类的聚类中心分别求欧氏距离,使得
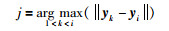
|
(1) |
arg max(·)表示在k=j处取得最小值,即找与yi欧氏距离最近的现有聚类j,欧氏距离为D3j.若D3j < δy,y3和j归为一类,求出新的聚类中心;若D3j>δy且若现有聚类数小于q,y3作为新的聚类,聚类中心为本身;若D3j>δy,且现有聚类数等于q,直接把yi归为j类,求出新的聚类中心.最终,在Y空间中得到e个聚类,其中e≤q.
Step 2 根据Y空间的e个聚类,找出对应的X空间元素在X空间中生成e个聚类(比如,y1、y3、y9在一个聚类中,根据映射关系,则x1、x3、x9就作为一个聚类),算出各自聚类中所有元素的均值作为聚类中心.
(1) 对X空间中的现有聚类进行一次均值聚类,使用马氏距离[24],其中基于概率的矩阵中,马氏负对数似然估计的定义如式(2)所示:
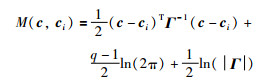
|
(2) |
其中,c与ci表示中心向量,Γ表示每个节点的散列矩阵,是q个聚类协方差矩阵Γi的均值:
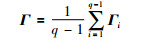
|
(3) |
(2) 再对X空间的i(i=1,2,…,e)聚类找到对应Y空间的元素,计算这些元素之间的欧氏距离D.
(3) 若D>δy,则X空间的i聚类生出一个子节点,再进行一次均值聚类(使用马氏距离).
(4) 循环步骤(2)、步骤(3),直至所有聚类都满足条件,建树成功.
图 2给出了IHDR树的建立过程及X、Y空间的映射关系图.

|
| 图 2 IHDR树结构与X、Y空间映射关系图 Figure 2 The structure of IHDR tree and the mapping relationship between X space and Y space |
在检索阶段,设得到X空间的待检索向量为x′t(x′t1,x′t1,…,x′ta),目标是通过x′t回归出对应的yt(yt为机器人“记忆中”,与x′t欧氏距离最近的xt对应在Y空间的运动控制量),其中要求x′t与yt在知识库对应的X空间中向量xt的欧氏距离最小,该最小欧氏距离记为d,如式(4)所示:
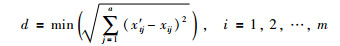
|
(4) |
Step 3 检索时,给定检索精度k.从第1层开始,计算每一层的每个聚类到x′t的距离.挑选出距离最小的前k个X空间聚类,把它们记为活跃聚类.设x′t到聚类c1的距离最小,把它们的距离值与检索敏感系数ε比较:如果小于ε,则检索结束,返回聚类c1的聚类中心对应的Y空间分量作为yt;否则,对每个活跃聚类按距离递增排序并依次处理.如果它有子节点,则取消该活跃聚类的标记,而是计算它的子节点.对于子节点,递归调用此过程,直到所有的活跃聚类都没有子节点.
在最终的所有活跃聚类中,设聚类c2到xt的距离最短,则输出聚类c2的聚类中心对应的Y空间分量作为yt,从而控制机器人实现导航.
3.2 基于最远距离优先机制的局部避障方法在IHDR树建立完毕后,先应用以下局部避障算法进行检测,满足避障条件则进行避障导航,不满足则进行IHDR树的检索实现导航.
本文使用的激光测距仪选自SICK公司(德国制造),型号为LMS200,最小检测距离为1 mm,本文扫描距离r≤8 m.设置激光角度分辨率为1°,扫描范围为0°~180°,则共有181根激光射线,获取的激光距离数据的单位为mm. SICK激光测距仪的正右方为0°方向,正左方为180°方向,从0°至180°分别收到的是对应方向上激光测距仪发射端与障碍物之间的距离数据.激光测距仪感知周围环境的工作原理示意图如图 3所示.

|
| 图 3 激光测距仪感知周围环境示意图 Figure 3 Schematic diagram of LRF sensing environment |
基于文[13]中提出的可行方向的求法,本文的避障算法分为以下步骤.
3.2.1 求可行方向Step 1 预先设定阈值Rt(依据机器人实际尺寸给定,本文为600 mm).将当前获取的SICK激光数据的0°~179°每3°为一个区间,分成60个小区间,依次编号Si(i=0,1,…,59).为了使各个小区间大小均匀,舍去了180°方向的激光数据.
Step 2 把每个小区间的距离数据与Rt进行比较,若小区间内的3个距离数据都大于Rt,则保留作为准可行小区间,否则舍去,不作为准可行小区间.
Step 3 合并所有相邻的准可行小区间,获得N个准可行大区间(若某小区间无相邻的准可行小区间则自成为一个准可行大区间).
Step 4 对N个准可行大区间进行弦长条件和矩形条件[13]的判断,满足两个条件的准可行大区间记为待选可行大区间.
3.2.2 最远距离优先机制Step 5 在Step 4得出的D个待选可行大区间中,计算每个区间中所有激光距离数据的最大值M(i).比如,设Di为D个待选可行大区间中的第i个待选可行大区间,若Di={2 013,1 023,879,231,344,112},则M(i)=2 013.若:
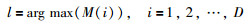
|
(5) |
则选择第l个待选可行大区间为参考行驶区间,并设此时的扇形区间的角平分线方向即为参考行驶方向L.
3.2.3 误差控制由于激光测距仪不处在机器人转向时的中心,在测量和控制中会不可避免地产生误差.为了算法的可实现性,本文在获取可行方向后,进行了以下控制误差的处理.
Step 6 若得出的参考行驶方向与90°方向的偏差小于15°,则不进行避障操作,直接进入IHDR树的检索,实现导航.当且仅当偏差大于15°时才进行避障转向操作,转动角度为
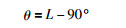
|
(6) |
其中θ为负数则表示右转,θ为正数则表示左转.
4 实验研究 4.1 移动机器人实验平台及其方案流程 4.1.1 实验平台实验中所使用的MT-R轮式移动机器人如图 4所示. MT-R轮式移动机器人共有5个行驶轮,其中有2个独立驱动轮和3个万向随动轮.上位机(Intel Core Duo CPU 1.86 GHz,内存1 GB)通过串口向运动控制卡发送指令,运动控制卡的PWM(pulse width modulation)信号输入到电机驱动器,作为电机驱动器的控制信号,通过调节PWM信号的占空比来改变机器人的运行速度.激光测距仪LMS200安装在机器人的正前方,通过RS232串口与移动机器人控制单元进行通信.实验中设置机器人直线运动速度为±0.2 m/s(+表示前进速度,-表示后退速度),左右转向速度为±10°/s(+表示左转速度,-表示右转速度).实验使用MFC(Microsoft Visual Studio 2008)编写软件界面.

|
| 图 4 MT-R轮式移动机器人 Figure 4 MT-R wheeled mobile robot |
实验过程中,由激光测距仪获取距离信息,维数为181.机器人的运动速度设定为(v,ω),维数为2,其中v对应沿直线运动的速度,ω对应左右转动的角速度.由于本文的直线运动速度和角速度为定值且同时刻仅进行一项操作(直线运动或转向运动),故任一场景下机器人对应的运动状态仅有5种,即Y空间中仅有5个向量,如图 5所示.

|
| 图 5 本文实验中X空间和Y空间的具体映射关系 Figure 5 The specific mapping relationship between X space and Y space in our experiment |
首先,根据周围环境特征与目标点位置,人为规划出供机器人行驶的最优路径后,使用计算机键盘上的方向键在上位机软件中控制机器人沿着规划好的路径进行运动和在线学习.在此过程中,开启定时器程序,定时时间为200 ms(采集频率为5 Hz),采集当前SICK激光测距仪返回的距离数据,将得到的SICK激光数据和对应的速度数据,根据IHDR算法存入到IHDR树中.当移动机器人到达目标点的同时,IHDR树也构建完毕.
然后,开启自适应导航,进行初始化设置、MFC中关闭和打开相关定时器和线程等程序操作,使轮式机器人开始自主运动;采集SICK激光数据,将其放入避障算法中进行检验,若结果得出无需进行避障操作则进行IHDR树的检索实现导航,反之则进行避障转向操作.
当基于学习机制的导航时,将采集到的SICK激光数据根据IHDR算法放入IHDR树中进行回归分析,从而得到回归结果,即IHDR树中对应Y空间的速度数据.再将该回归结果放入控制轮式机器人运动的函数当中,实现机器人导航操作.详细的自适应导航实验流程图如图 6所示.

|
| 图 6 自适应导航实验流程图 Figure 6 The flow chart of adaptive navigation experiment program |
为展示基于单一学习机制的导航的性能,本实验使MT-R机器人在实验场地进行导航.首先使用计算机键盘上的方向键,在上位机软件中,控制机器人沿着人为规划的路径进行运动和在线学习.在学习的过程中,以200 ms的间隔采集SICK激光数据,并对应识别当前键盘方向键的键值,得出当前机器人的速度数据.然后将每次得到的SICK激光数据(X空间,181维)和对应的速度数据(Y空间,2维)根据IHDR算法存入到IHDR树中.一直控制MT-R机器人沿着预定路径进行运动直到到达终点,IHDR树建立完毕.
之后开启基于单一学习机制的导航,在导航过程中,实时采集SICK激光数据,放入IHDR树中进行检索(即把当前场景的SICK激光数据放入IHDR树中,检索之前“记忆”中包含信息相近的场景),回归出速度数据,以此控制MT-R机器人运动实现自主导航.实现结果如图 7和图 8所示.

|
| 图 7 学习样本和回归样本的直线速度对比图 Figure 7 The contrast of linear velocity between learning samples and regression samples |

|
| 图 8 学习样本和回归样本的转向速度对比图 Figure 8 The contrast of angular velocity between learning samples and regression samples |
图 7中,红点表示MT-R机器人进行在线学习某段路径时,记录下的100组样本的直线速度值,相邻两个记录之间的时间间隔为200 ms.绿色方框表示MT-R机器人重新位于相同静态场景的导航路径下,当进行基于单一学习机制的自主导航时,回归出的直线速度值.
图 8为相同场景下,MT-R转向速度对比图.其中当直线速度为0时,MT-R机器人的转向速度非零;当转向速度为0时,MT-R机器人的直线速度非零.
由图 7和图 8可知,当导航的环境为静态环境时,图中绿色方框大部分与红点重合,即MT-R机器人基于IHDR算法可以较好地回归出正确的速度数据.因此,由图 7和图 8可以说明基于单一学习机制的导航可以使MT-R机器人在静态场景中按预定路径进行运动.而图中有差异的部分主要是由于在学习与回归过程中,不可避免的程序延时、控制误差、场景细微变化等因素造成.
然而,当在自主导航场景中,人为动态地放置一个空矿泉水瓶作为障碍物时(因为此时导航场景和之前的学习场景相比发生了变化,故基于单一学习机制的导航在预期中会发生碰撞,安全起见,故选用较轻的空矿泉水瓶作为障碍物),当前场景与学习时的导航场景相比较就发生了变化,此时基于单一学习机制的MT-R机器人的导航实验视频截图如图 9所示. 图 9(a)~图 9(d)为实验视频中的顺序截图.由图 9可知,此时的MT-R机器人仍然根据“记忆”中的导航路径选取与当前场景最接近的运动控制量.但是,由于人为新增的一个矿泉水瓶,使得导航场景变成了动态的,仅依靠之前的学习经验并不能使MT-R机器人很好地适应新的动态场景,因此实验最终结果为MT-R机器人撞上了障碍物.可见,一旦遇见了动态场景,基于单一学习机制的导航方法就不能有效的进行导航.

|
| 图 9 基于单一学习机制的导航实验视频截图 Figure 9 The screenshots of experiment video only based on learning mechanism |
使用自适应导航实验方案,控制MT-R机器人在与上述基于单一学习机制相同的实验场景下(无矿泉水瓶)进行学习,同样在自主导航场景中,人为动态添入一个矿泉水瓶作为障碍物,实验视频截图如图 10所示.

|
| 图 10 基于本文导航方法的实验视频截图 Figure 10 Thescreenshots of experiment video based on the proposed navigation method |
图 10(a)~图 10(d)为实验视频中的顺序截图,每张截图的右半部分,为实验过程中实时对应的控制MT-R机器人的上位机界面.界面中上半部分为当前环境的激光扫描地图,地图中红色的点表示激光扫描点,绿色的半圆表示本文局部避障算法的阈值范围,半圆中的黑色矩形表示MT-R机器人的头部轮廓. 图 10(a)标出了障碍物(矿泉水瓶)对应在激光扫描地图上的位置.在图 10(b)中,MT-R机器人正在基于本文的局部避障算法进行避障操作,而在其余的图 10(a)、10(c)、10(d)中MT-R机器人是基于IHDR算法进行自主导航.从图 10可知,由于本文导航方法对动态场景的自适应能力,MT-R机器人很好地避过了局部障碍物,并且之后继续基于IHDR算法沿着之前学习的路径进行自主导航.
现使导航场景进一步复杂,让实验员在机器人前方的不同的位置动态地阻挡机器人运动,实验视频截图如图 11所示. 图 11(a)~图 11(f)为实验视频中的顺序截图,可见实验员突然出现在机器人的右前方位置(图 11(a)),而机器人运用本文局部避障机制绕过实验员后继续进行基于学习机制的导航(图 11(b)至图 11(c)),此时实验员再移动到机器人的左前方位置(图 11(d)),此时机器人再次运动局部避障机制,成功避开实验员,继续基于学习机制进行导航(图 11(e)至图 11(f)).实验员两次突然出现在机器人运动方向上,基于自适应导航方法的机器人都成功地避开了实验员,并且避开之后仍基于IHDR树中的“记忆”,沿着之前学习的路径进行导航,实现了全局路径规划和局部动态避障的自适应能力.

|
| 图 11 实验员动态阻挡机器人实验视频截图 Figure 11 Thescreenshots of experiment video with the assistant tending to hinder MT-R robot |
为展示本文提出的基于最远距离优先机制的局部避障算法的原理与性能,本文选取了具有代表性的两种局部环境障碍场景,依次命名为S1、S2,其中场景S2的实拍图如图 12所示.

|
| 图 12 S2场景实拍图 Figure 12 The photo of the scene S2 |
场景中的障碍物为长方体纸箱.使MT-R机器人分别处于在两种场景中,获取MT-R机器人在两种场景中实时的局部环境激光数据,并将这些数据送至本文算法进行计算.最后对MT-R机器人在两种场景中的激光数据和计算后的结果进行极坐标绘图,得到S1、S2的避障算法计算结果图,如图 13所示.这两种场景经过本文算法计算后的主要结果显示在表 1中.

|
| 图 13 两种场景下的分析结果图 Figure 13 Analysis result figures in two scenes |
| 障碍场景 | 待选可行大区间 | 最远距离所在区间 | 最远距离值 | 参考行驶区间 | 参考行驶方向 |
| S1 | Ⅰ:(0°,71°),Ⅱ:(102°,179°) | Ⅱ | 3 221 | Ⅱ | 140° |
| S2 | Ⅰ:(0°,38°),Ⅱ:(51°,131°),Ⅲ:(141°,179°) | Ⅱ | 4 927 | Ⅱ | 91° |
图 13(a)、(b)分别对应场景S1、S2. S1位于含有障碍物的走廊中,在MT-R的右前方放了一个纸箱. S1为MT-R与障碍物的距离刚小于阈值时的场景,由计算结果可知在S1中得到了两个参考区间,根据最远距离优先机制,最远距离处在区间Ⅱ中,故选择区间Ⅱ作为参考区间,它的角平分线方向作为参考行驶方向. S2位于一个比S1更宽的走廊中,场景S2的实拍图如图 12所示,在MT-R右前方和左前方分别有一个障碍物,由计算结果可知,在S2中得到了3个参考区间,最远距离处在区间Ⅱ中,故选区间Ⅱ为参考区间.由两种场景下的计算结果可知,最远距离优先机制使得机器人始终朝着逃离局部障碍区的方向进行运动.
在该避障算法开始运行时作为计时起点,一次计算完成时作为计时终点,在实验过程中对该算法的10次计算进行计时,得出的时间数据进行统计分析,结果如表 2所示.
由表 2可见,该避障算法具有较好的实时性,并可知该避障算法能高效地作为避障判断条件,用于基于学习机制的导航中.
5 结论本文提出了一种基于学习机制的移动机器人动态场景自适应导航方法,摆脱了传统导航方法对建立环境模型的过度依赖,提高了基于单一学习机制的移动机器人导航在动态环境下的自适应能力. MT-R机器人的速度样本对比图证实了基于学习机制的导航方法在静态场景下的良好表现.应用在MT-R机器上,与基于单一学习机制导航方法的对比实验及实验员阻挡实验,验证了本文方法的可行性及在动态环境下的自适应能力.基于最远距离优先机制的局部避障算法的性能分析实验,显示了本文提出的避障算法的作用原理与良好的实时性表现.实验结果显示,通过结合学习机制和局部避障算法这两种导航方法,移动机器人在动态场景的导航中获得了较好表现.后续将进一步研究如何继续结合其它导航方法,提高移动机器人在未知环境下的导航能力.本文的方法可为移动机器人避障,导航及路径规划相关领域提供实际参考.
| [1] | Kruse T, Pandey A K, Alami R, et al. Human-aware robot navigation:A survey[J]. Robotics and Autonomous Systems , 2013, 61 (12) : 1726–1743. DOI:10.1016/j.robot.2013.05.007 |
| [2] | Tan F, Yang J, Huang J, el al. A navigation system for family indoor monitor mobile robot[C]//2010 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, NJ, USA:IEEE, 2010:5978-5983. |
| [3] | Li G, Tamura Y, Yamashita A, et al. Effective improved artificial potential field-based regression search method for autonomous mobile robot path planning[J]. International Journal of Mechatronics and Automation , 2013, 3 (3) : 141–170. DOI:10.1504/IJMA.2013.055612 |
| [4] | AL-Taharwa I, Sheta A, Al-Weshah M, et al. A mobile robot path planning using genetic algorithm in static environment[J]. Journal of Computer Science , 2008, 4 (4) : 341–344. DOI:10.3844/jcssp.2008.341.344 |
| [5] | Tamilselvi D, Mercy Shalinie S, Hariharasudan M, et al. Optimal path selection for mobile robot navigation using genetic algorithm in an indoor environment[J]. International Journal of Computer Science , 2011, 8 (4) : 433–440. |
| [6] | Zeng C, Zhang Q, Wei X. GA-based global path planning for mobile robot employing A*algorithm[J]. Journal of Computers , 2012, 7 (2) : 470–474. |
| [7] | Ok K, Ansari S, Gallagher B, et al. Path planning with uncertainty:Voronoi uncertainty fields[C]//2013 IEEE International Conference on Robotics and Automation. Piscataway, NJ, USA:IEEE, 2013:4581-4586. |
| [8] | Cristoforis P D, Nitsche M, Krajnik T, et al. Hybrid vision-based navigation for mobile robots in mixed indoor/outdoor environments[J]. Pattern Recognition Letters , 2015, 53 (1) : 118–128. |
| [9] | 战强, 吴佳. 未知环境下移动机器人单目视觉导航算法[J]. 北京航空航天大学学报 , 2008, 34 (6) : 613–617. Zhan Q, Wu J. Monocular vision-based navigation algorithm for mobile robots in unknown environments[J]. Journal of Beijing University of Aeronautics and Astronautics , 2008, 34 (6) : 613–617. |
| [10] | 杨东方, 王仕成, 刘华平, 等. 基于Kinect系统的场景建模与机器人自主导航[J]. 机器人 , 2012, 34 (5) : 581–589. Yang D F, Wang S C, Liu H P, et al. Scene modeling and autonomous navigation for robots based on kinect system[J]. Robot , 2012, 34 (5) : 581–589. DOI:10.3724/SP.J.1218.2012.00581 |
| [11] | Saito H, Amano R, Moriyama N, et al. Emergency obstacle avoidance module for mobile robot using a laser range finder[C]//Proceedings of SICE Annual Conference 2013, Piscataway, NJ, USA:IEEE, 2013:348-353. |
| [12] | Básaca-Preciado L C, Sergiyenko O Y, Rodríguez-Quinonez J C, et al. Optical 3D laser measurement system for navigation of autonomous mobile robot[J]. Optics and Lasers in Engineering , 2014, 54 (1) : 159–169. |
| [13] | 徐玉华, 张崇巍, 徐海琴. 基于激光测距仪的移动机器人避障新方法[J]. 机器人 , 2010, 32 (2) : 179–183. Xu Y H, Zhang C W, Xu H Q. A new obstacle avoidance method of mobile robot based on laser range finder[J]. Robot , 2010, 32 (2) : 179–183. DOI:10.3724/SP.J.1218.2010.00179 |
| [14] | 王蛟龙, 周洁, 高慧, 等. 基于局部环境形状特征识别的移动机器人避障方法[J]. 信息与控制 , 2015, 44 (1) : 91–98. Wang J L, Zhou J, Gao H, et al. Obstacle avoidance method for mobile robots based on the identification of local environment shape features[J]. Information and Control , 2015, 44 (1) : 91–98. |
| [15] | Zeng S Q, Weng J Y. Online-learning and attention-based approach to obstacle avoidance using a range finder[J]. Journal of Intelligent and Robotic System , 2007, 50 (3) : 219–239. DOI:10.1007/s10846-007-9162-9 |
| [16] | Chen Y, Cheng L, Wu H Y, et al. Knowledge-driven path planning for mobile robots:Relative state tree[J]. Soft Computing , 2015, 19 (3) : 763–773. DOI:10.1007/s00500-014-1299-4 |
| [17] | 段勇, 徐心和. 基于模糊神经网络的强化学习及其在机器人导航中的应用[J]. 控制与决策 , 2007, 22 (5) : 525–534. Duan Y, Xu X H. Reinforcement learning based on FNN and its application in robot navigation[J]. Control and Decision , 2007, 22 (5) : 525–534. |
| [18] | 陈洋, 张道辉, 赵新刚, 等. 基于IHDR自主学习框架的无人机3维路径规划[J]. 机器人 , 2012, 34 (5) : 513–518. Chen Y, Zhang D H, Zhao X G, et al. UAV 3D path planning based on IHDR autonomous-learning-framework[J]. Robot , 2012, 34 (5) : 513–518. DOI:10.3724/SP.J.1218.2012.00513 |
| [19] | Vernon D, Metta G, Sandini G. A survey of artificial cognitive systems:Implications for the autonomous development of mental capabilities in computational agents[J]. IEEE Transactions on Evolutionary Computation , 2007, 11 (2) : 151–181. DOI:10.1109/TEVC.2006.890274 |
| [20] | Kawamura K, Gordon S M, Ratanaswasd P, et al. Implementation of cognitive control for a humanoid robot[J]. International Journal of Humanoid Robotics , 2008, 5 (4) : 547–586. DOI:10.1142/S0219843608001558 |
| [21] | Grüneberg P, Suzuki K. An approach to subjective computing:A robot that learns from interaction with humans[J]. IEEE Transactions on Autonomous Mental Development , 2014, 6 (1) : 5–18. DOI:10.1109/TAMD.2013.2271739 |
| [22] | Li W L, Wu H Y, Chen Y, et al. Autonomous navigation experiment for mobile robot based on IHDR algorithm[C]//5th Annual IEEE International Conference on Cyber Technology in Automation, Control and Intelligent Systems, Piscataway, NJ, USA:IEEE, 2015:572-576. |
| [23] | Weng J Y, McClelland J, Pentland A, et al. Autonomous mental development by robots and animals[J]. Science , 2001, 291 (5504) : 559–600. |
| [24] | Weng J Y, Hwang W S. Incremental hierarchical discriminant regression[J]. IEEE Transactions on Neural Networks , 2007, 18 (2) : 397–415. DOI:10.1109/TNN.2006.889942 |